
Une des problématique rencontrée en business intelligence est le calcul de cumuls, le fameux « year to date » pour les connaisseurs, dans cet article, je présenterai différentes techniques dont l’utilisation du langage MDX.
Introduction
Je ne donnerai pas un cours de MDX dans cet article, je me contenterai de vous donner son historique et sa définition, qui je l’espère sera la plus claire possible, j’expliquerai sa venue dans le monde open source, puis je finirai par un exemple concret de son utilisation en BI, je vous donne également tous les liens pour reproduire ma démo ainsi que la documentation pour bien débuter.
Les origines
Ce langage a été créé en 1998 par Microsoft, vous l’aurez compris, il est propriétaire et toujours utilisé à l’heure actuelle dans les produits tel que Microsoft SQL Server Analysis Services en relation étroite avec la DB SQL Server 2012.
Définition
Le MDX pour « Multidimensional Expressions » est un langage de requête dédié aux données structurées de manière multidimensionnelles. C’est un langage exclusivement réservé à l’analytique avec lequel on ne peut donc faire que de l’interrogation, pas de DML (manipulation) ni de DDL (gestion de la structure), les requêtes sont conçues plus rapidement qu’avec du SQL classique.
En résumé, le MDX est à la base de données OLAP ce que SQL est pour la base de données relationnelle classique.
Quid de l’open source
Pour utiliser le MDX dans le monde open source, il est nécessaire de connaitre un peu l’historique et le vocabulaire qui lui est propre.
Serveur Mondrian
En 2002 sort le projet Mondrian, développé en java ce serveur est en fait un moteur qui utilise un driver OLAP pour piloter une base de données relationnelle classique (ROLAP). Le serveur Mondrian est capable d’exécuter des requêtes MDX et de restituer le résultat au format multidimensionnel. Voir la Documentation Mondrian
Driver OLAP
L’API OLAP4J développé également en java embarque nativement un driver JDBC, ce driver fait le lien entre le serveur Mondrian et le serveur de base de données relationnel et peu importe la DB pour autant que vous fournissiez le bon jar correspondant (Mysql, Oracle, SQL Server, DB2). Voir la documentation OLAP4J
Schéma OLAP
Un schéma est un fichier XML qui fournit une description d’une base de données multidimensionnelle, un modèle qui décrit cubes, hiérarchies et membres basés sur des données physiques.
Base de données OLAP
Ce type de base de données est l’addition d’une base de données relationnelle et d’un schéma OLAP (mapping XML) qui la décrit sous forme de cubes.
Démonstration
Pour cette démonstration j’utiliserai JasperAnalysis Workbench (cliquer pour télécharger) qui se connectera à une base de données MySql, la documentation complète de cet outil se trouve dans l’archive ZIP.
Jasperanalysis Workbench est un outil un peu tombé en désuétude depuis sa version 4.0, c’est un éditeur de schéma OLAP qui va vous aider à créer un fichier XML de toutes pièces, cerise sur le gâteau, il permet une fois le fichier XML créé, de l’utiliser pour se connecter à une base de données (devenue OLAP) et de lancer des requêtes MDX.
Sachez aussi que cet outil vous est utile si vous désirez faire de l’OLAP avec JasperServer version communautaire, ce principe tombe à l’eau si vous utilisez la version professionnelle.
Vous pouvez télécharger la base de données de test très connue nommée FoodMart et son schéma OLAP qui lui correspond. Je mets ce lien sur mon domaine car j’ai adapté le script SQL de chargement sur une base de données MySQL Version 5.
Parce qu’un dessin vaut toujours mieux qu’un long discours, voici ce que donne l’ensemble des notions que j’ai expliqué le long de cet article:
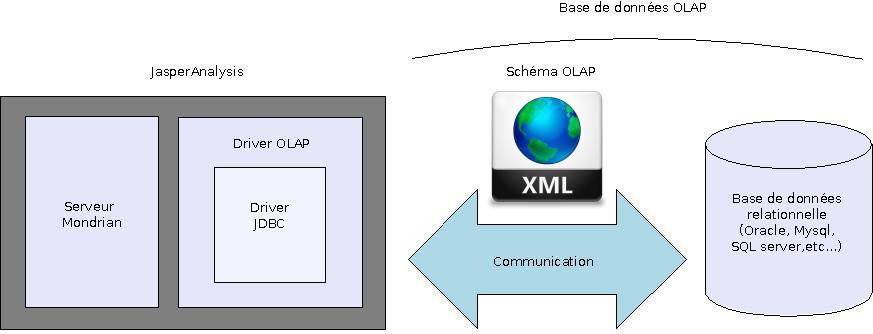
Faire des cumuls
Avant de se lancer dans le MDX, sachez que vous pouvez faire des calculs de cumuls en langage SQL, il existe plusieurs techniques, j’expliquerai celles dont j’ai connaissance (il en existe surement d’autres).
Méthode SQL générique
Cette méthode fonctionne sur toutes les bases de données utilisant le SQL standard, il n’y a pas de fonction spécifique dans cette requête. La technique est d’appeler une seconde fois la requête pour la placer dans un nouveau champ, il faut ensuite utiliser un signe « inférieur ou égal » entre les champs mois qui sont triés.
SELECT pc.product_family, t.the_year, t.quarter, t.month_of_year, SUM(f.store_sales) AS store_sales, -- Nouveau champ issu de la requête d’origine (SELECT SUM(f1.store_sales) FROM foodmart.sales_fact_1997 f1 INNER JOIN product p1 ON p1.product_id = f1.product_id INNER JOIN product_class pc1 ON pc1.product_class_id = p1.product_class_id INNER JOIN time_by_day t1 ON t1.time_id = f1.time_id WHERE pc1.product_family ='Drink' -- on compare les champs mois afin de cumuler les montants AND t1.month_of_year <= t.month_of_year GROUP BY pc1.product_family, t1.the_year ORDER BY t1.the_year, t1.quarter, t1.month_of_year) as cumul FROM foodmart.sales_fact_1997 f INNER JOIN product p ON p.product_id = f.product_id INNER JOIN product_class pc ON pc.product_class_id = p.product_class_id INNER JOIN time_by_day t ON t.time_id = f.time_id WHERE pc.product_family ='Drink' GROUP BY pc.product_family, t.the_year, t.quarter, t.month_of_year ORDER BY t.the_year, t.quarter, t.month_of_year
Méthode Mysql
Ici j’utilise une variable incrémentale, les mots clés utilisés sont spécifiques à MySql.
-- définition d'une variable temporaire qui va accumuler chaque montant SET @sum:= 0; SELECT t1.*, @sum:=@sum + store_sales AS cumul FROM ( SELECT pc.product_family, t.the_year, t.quarter, t.month_of_year, sum(f.store_sales) as store_sales FROM foodmart.sales_fact_1997 f INNER JOIN product p on p.product_id = f.product_id INNER JOIN product_class pc on pc.product_class_id = p.product_class_id INNER JOIN time_by_day t on t.time_id = f.time_id WHERE pc.product_family ='Drink' GROUP BY pc.product_family, t.the_year, t.quarter, t.month_of_year ORDER BY t.the_year, t.quarter, t.month_of_year) t1
Résultat des deux méthodes:
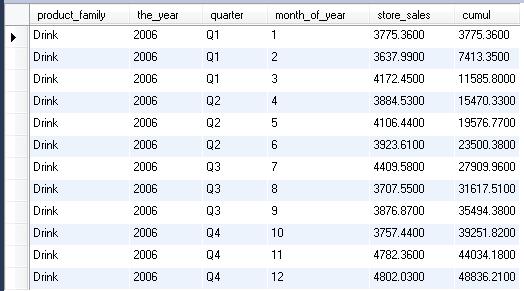
Méthode Oracle
Ici je sors un peu du monde open-source pour vous donner une méthode spécifique à Oracle, en effet cette base de données possède des fonctions analytiques, dont vous trouverez un excellent tutoriel sur le site de developpez.com
Comme il est plus difficile d’utiliser Oracle, vous pouvez utiliser SQL Fiddle un site de test SQL très bien conçu et très utile.
Voici l’exemple que j’ai pris soin de sauvegarder :
CREATE TABLE test (id number, year number, month number, amount number);
INSERT INTO test VALUES (1,2013,1,1000); INSERT INTO test VALUES (2,2013,2,2000); INSERT INTO test VALUES (3,2013,3,3000); INSERT INTO test VALUES (4,2013,4,4000); INSERT INTO test VALUES (5,2013,5,5000); INSERT INTO test VALUES (6,2013,6,6000); INSERT INTO test VALUES (7,2013,7,7000); INSERT INTO test VALUES (8,2013,8,8000); INSERT INTO test VALUES (9,2013,9,9000); INSERT INTO test VALUES (10,2013,10,10000); INSERT INTO test VALUES (11,2013,11,11000); INSERT INTO test VALUES (12,2013,12,12000);
SELECT id, year, month, amount, SUM(amount) OVER (PARTITION BY year ORDER BY month) AS cumul FROM test;
Le résultat de la fonction analytique d’oracle
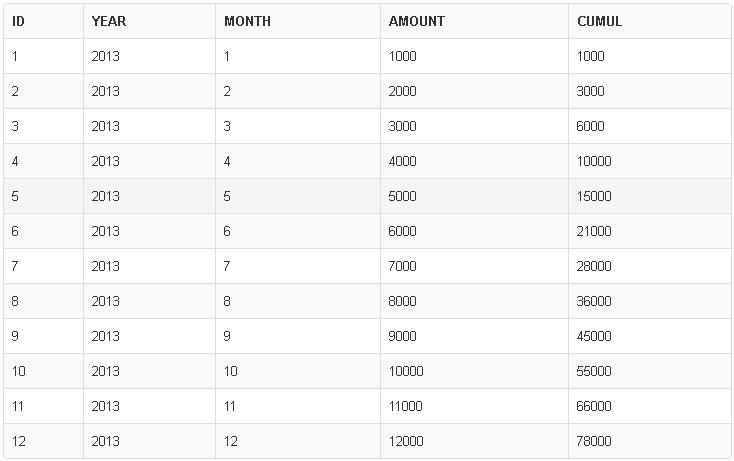
Résultat fonction analytique oracle
Méthode MDX
C’est ce dernier cas qui nous intéresse tout particulièrement, pour en savoir plus sur le langage MDX, rendez-vous sur la page du site de Microsoft qui donne toutes les références de ce fabuleux langage
Structure du langage MDX
Pour vous donner une idée je vais rapidement décrire ici, comment s’articule la construction d’une requête MDX.
SELECT [Niveau].[Membres] et/ou [MESURES] ON COLUMNS
[Niveau].[Membres] et/ou [MESURES] ON ROWS
FROM [Cube]
WHERE [Condition]
Composé des éléments suivants
| Eléments | Exemples |
| Dimension
->Hiérarchies ->Niveaux ->Membres |
Temps
-> (Année-Trimestre-Mois), (Année-Semaine) -> Année OU trimestre OU Mois OU Semaine -> 2006, Q3, 10 |
Dimension :
Elément qui compose les faits
Hiérarchie :
Ensemble de plusieurs niveaux
Niveau :
Décomposition de la dimension
Membre :
Valeur que peut prendre un niveau
Pour calculer des cumuls en MDX, il existe une fonction qui se nomme YTD() , elle fonctionne avec la clause WITH MEMBER qui permet de calculer de nouveaux membres, un peu comme la technique d’une variable incrémentale.
WITH MEMBER [Measures].[Cumul]
as Sum(YTD(), [Measures].[Store Sales])
SELECT
{( [Measures].[Store Sales]) , ([Measures].[Cumul] )} ON COLUMNS,
[Product].[Drink] * Descendants([Time].[2006],2)
ON ROWS
FROM [Sales 2]
Résultat de la requête MDX
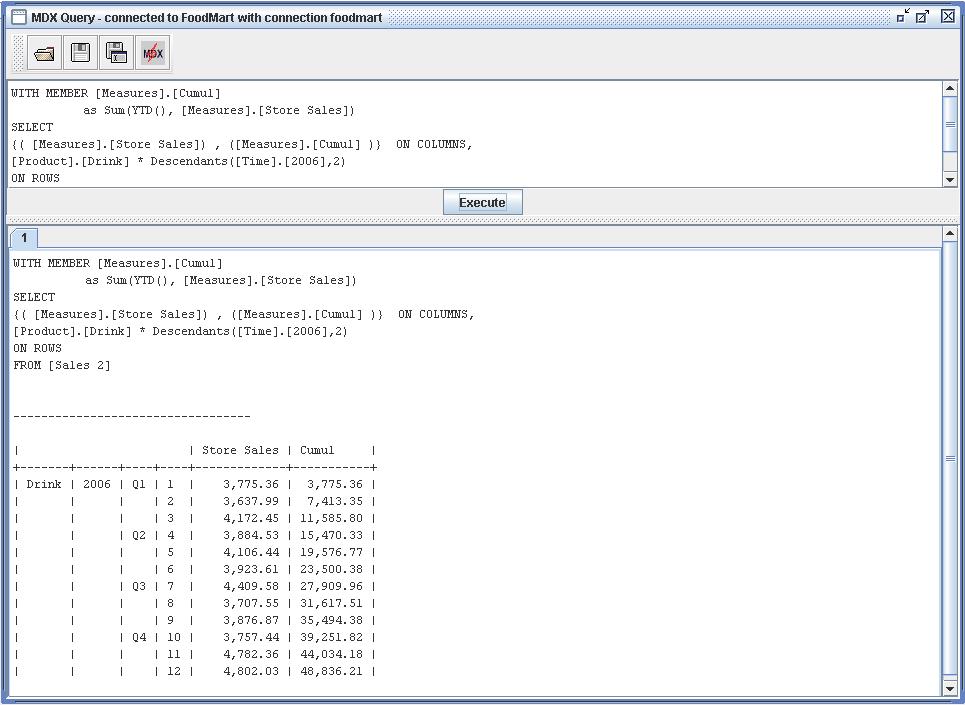
Conclusion
Avec le langage SQL, il faut considérer le fait qu’il devient très fastidieux de créer des requêtes analytiques, on peut toutefois réussir à obtenir le résultat escompté mais au prix de requêtes à rallonge et souvent difficilement maintenable.
Le MDX intervient donc avec une syntaxe épurée et une meilleure facilité de compréhension, malheureusement peu de gens le connaissent, hormis bien sûr les utilisateurs des solutions BI Microsoft.
Enfin, mon dernier conseil sera de vous rediriger (encore une fois) sur l’excellent outil Saiku cela vous permettra de monter graduellement en puissance sur ce langage en assimilant des requêtes MDX générées automatiquement.
