
Le BigData commence là où les bases de données abandonnent, cet article parle aussi de la technologie Hadoop, quand et comment l’utiliser, ainsi que son lien avec le BigData et la Business Intelligence.
Le BigData
Dans cet article orienté théorique, je vais tenter de démystifier le sujet, je ne vais pas vous assommer avec des définitions trop techniques comme celle des 3V de Gartner (Vélocité, Volume, Variété) que l’on peut trouver ici, de mon point de vue, le BigData est la capacité à gérer de manière efficace des quantités de données importantes mais attention que ce n’est pas une solution magique, comme des problèmes de lenteur de certaines base de données, certains projets bien spécifiques collent parfaitement à l’utilisation du BigData, tout n’est donc pas utilisable de manière efficace avec la solution BigData.
La problématique
Depuis la banalisation des appareils électroniques intelligents et l’utilisation massive d’internet, la quantité de données générée a explosé, une nouvelle problématique est née: « Comment stocker une quantité exponentielle de données et les exploiter dans des délais acceptable ? ». Il est vrai que de simples bases de données relationnelles ne pourraient pas gérer de manière efficace le demi milliard d’utilisateurs Facebook et les 100 péta octets (1015) que la société dispose ou les millions de Tweets envoyés quotidiennement.
Hadoop
Hadoop est un écosystème écrit en java composé de plusieurs outils ayant chacun une tâche spécifique pour gèrer le BigData. Pour en savoir plus sur Hadoop, il existe un wiki qui lui est dédié.
Les distributions commerciales
Il existe deux distributions commerciales fournissant tous les outils nécessaires en package afin de créer un environnement Hadoop
Chaque société propose un package communautaire (gratuit) et professionnel avec des services payants.
HDFS
Tout cet ensemble repose sur un système de fichier nommé HDFS pour Hadoop Distribued File System, ce n’est donc pas une base de données mais bien un système de fichier que nous connaissons tel que NTFS pour Windows ou Ext4 pour Linux. La différence est que ce système de stockage utilise de gros blocs de 64mo (la tendance serait même de 128mo car le taux de transfert augmente avec le temps contrairement à la vitesse de recherche). L’avantage est d’accélérer la recherche des infos sur des volumes importants, moins de bloc donc plus d’efficacité. De plus, HDFS gère la redondance des informations en copiant les données sur plusieurs nœuds (par défaut en 3 exemplaires), cela résout également au passage la problématique de sauvegarde.
Fonctionnement HDFS
Ce système décentralisé fonctionne comme en cluster composé d’un nombre indéfini de machines qui sont appelées des nœuds, plus les nœuds sont en grand nombre et plus le cluster est performant.
Le principe est de tolérer les pannes car si un nœud tombe, cela n’affectera pas le fonctionnement du cluster, de plus, une fois réparé, il sera réintégré de manière transparente.
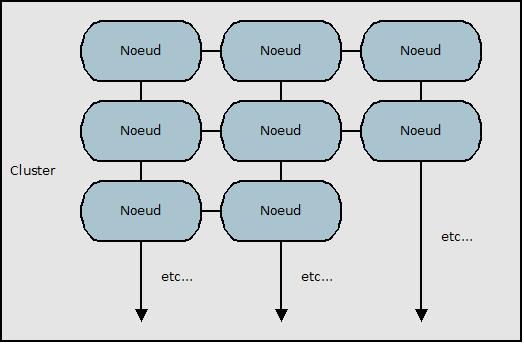
Les différents types de nœuds
Tous les nœuds qui composent le cluster ne sont évidemment pas identiques, mon schéma est trop générique et donne simplement une vision globale, je vais décrire plus précisément, les différents types de nœuds et leur utilité:
| Type | Nom du noeud | Remarques |
| Primaire | NameNode | Contient les méta-données, l’index des blocs contenant les fichiers |
| Primaire | SecondaryNameNode | Effectue de la maintance pour le compte du NameNode à intervalle réguliers pour le décharger |
| Secondaire | DataNode | Les blocs de données qui sont situés sur chaque nœud |
MapReduce
C’est un modèle de calcul et d’exécution en parallèle basé sur le modèle clé/valeur, les tâches à effectuer se font sur de gros volume de données et sont divisées à travers le cluster puis toutes les réponses sont ensuite agrégées, même s’il semblerait agir en deux étapes, il se passe également une étape intermédiaire de tri nommé « sort and shuffle ».
L’étape de « map »
Diviser les données en plusieurs parts plus ou moins égales afin de répartir la charge sur les différents mappers qui composent le cluster.
L’étape du « reduce »
C’est l’étape de fusion par les reducers de tous les résultats obtenues dans la phase de map.
Il faut noter que certaines opérations sont naturellement plus efficace avec ce mode de fonctionnement (comptage, retrouver un minimum ou un maximum, etc…)
YARN
Pour Yet Another Ressource Negotiator, c’est une évolution de Hadoop (version 2) qui améliore des fonctionnalités de MapReduce en séparant la gestion des ressources et la surveillance des jobs. Il est possible d’éttribuer d’autres tâches que du MapReduce aux différents noeuds d’un cluster.
L’environnement et outils Hadoop
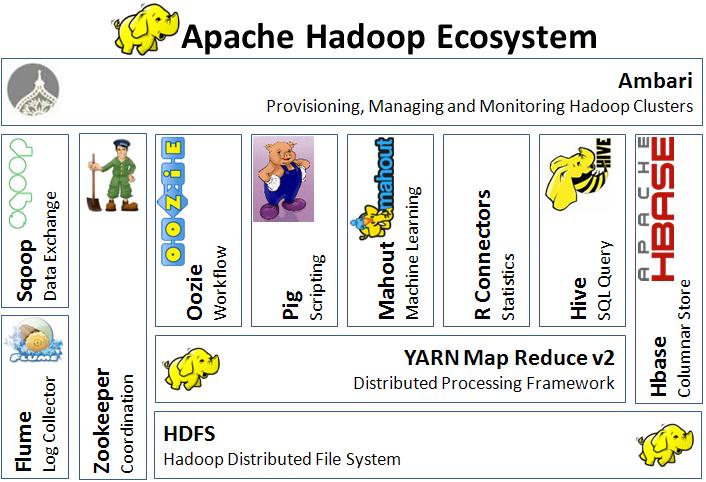
C’est un langage de scripting développé pour interroger les données dans Hadoop en frontend, l’avantage étant d’accélerer le développement en limitant les connaissances techniques en java. (Il faut beaucoup plus de lignes en langage java pour interroger les données).
Hive QL est un langage dérivé du SQL permettant aux ETL un accès simplifié aux données hébergées sur HDFS, le SQL est traduit de manière transparente.
Hadoop database, est une base de données distribuée orientée colonne et adaptée au BigData, elle fonctionne obligatoirement avec ZooKeeper.
Pour SQL on Hadoop, c’est un outil de transfert entre Apache Hadoop, Hive ou HBase et une base de données relationnelle classique.
C’est un service de centralisation et de synchronisation de systèmes, utilisé avec Hadoop pour la gestion des nœuds dans le cluster.
C’est un planificateur graphique de jobs et de flux dans Hadoop, permet de planifier des tâches MapReduce, Pig, Sqoop ou Hive.
Conclusion
Grâce aux outils de lecture basés sur le SQL, BigData est parfaitement adapté à la Business Intelligence et à l’analytique (OLAP) car une fois l’écriture de masse terminée, on y accède de nombreuse fois, tout l’inverse d’une DB classique qui a plutôt tendance à être accédée en écriture. Mon prochain article sera plus technique, je proposerai une installation des outils et un exemple concret d’utilisation.