
Voici une base de données très performante que j’ai découvert il y a peu, sa particularité est d’être orientée colonne et basée sur une DB Mysql (sorte de fork).
Surtout utilisée en analytique, elle permet de repousser les limitations des bases de données classiques. La version testée dans cet article est la version communautaire sous licence GPL estampillée 2.2.11.
Principe
Comme son nom l’indique le principe est de sérialiser les données: Définition de l’orienté colonnes sur wikipédia
Dans une requête, seules les colonnes nécessaires sont atteintes plutôt que des lignes entières, cela va réduire considérablement l’activité I/O, ce qui est non négligeable pour l’analytique qui consiste à remonter d’énormes quantités d’informations.
Un énorme avantage est que l’utilisation des index est inutile, un tri est fait naturellement, il est vrai qu’une base de données classique va devoir gérer une plus en plus grosse quantité d’index au fur et à mesure de l’augmentation de la taille de la base de données, en analytique il est très difficile de prévoir où placer les index, les rapports étant dynamiques.
Architecture
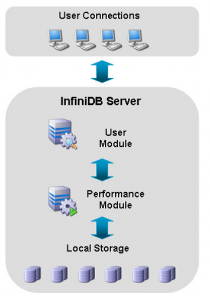
Module utilisateur (user module)
Ce processus appelé « ExeMgr » qui écoute sur un port TCP/IP, s’occupe de distribuer les requêtes au niveau plus bas, il ne touche pas aux fichiers de la base et n’a aucune visibilité sur eux.
Il est aussi composé d’un module directeur (interface MySql), c’est une instance qui permet de faire des opérations de base (connexion, requête, etc…).
En résumé il gère les demandes de l’utilisateur pour les transformer en une liste de job propre à InfiniDB, il appelle le ou les module(s) performance(s) situé(s) en dessous de lui, et retourne le résultat à l’utilisateur.
Module performance
Ce processus appelé « PrimProc » qui écoute sur un port TCP/IP les demandes traduites du module utilisateur, exécute les opérations d’I/O, puis rapatrie les données pour les mettre en cache. Ce module peut s’exécuter en mode multithread dans la version entreprise.
Stockage
Le stockage est soit local soit partagé, un fichier est créé pour une colonne de table. (bloc, extension, segment, partition)
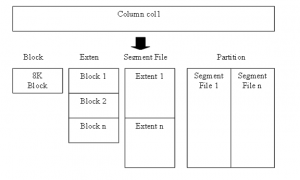
- Bloc : Objet physique aussi appelé page dans d’autres SGBD
- Extension : Mesure logique de 8 millions de lignes
- Segment : Un fichier physique sur disque qui contient une colonne
- Partition : Contient les segments
La carte étendue (extend map)
Décharge l’utilisateur de créer des index, des vues, des partitionnements manuel, etc…
C’est un bloc logique d’espace qui peut s’étendre de 8 à 64mo selon le type d’une colonne qui va contenir le même nombre de lignes. InfiniDB n’extrait que le bloc demandé, ces blocs sont rangés par plage de valeurs. Cette élimination des blocs non désirés est accélérées par le principe de l’orienté colonne.

Cette technique réduit les I/O en éliminant les blocs non nécessaires, mieux, en cas de filtre impossible, aucune I/O n’est exécutée.
Installation
De toutes les distributions que j’ai pu tester (ubuntu, centos, fedora, openSuse), celle qui est sortie du lot restera sans doute debian, beaucoup de package d’installation lui sont dédiés.
Télécharger le package calpont-infinidb-release#.amd64.deb.tar.gz (DEB 64-BIT) et placer le dans un répertoire de votre serveur.
Décompacter le tarball qui va générer trois paquets DEB
sudo tar -zxf calpont-infinidb-release#.amd64.deb.tar.gz
Installer les 3 paquets, la base de données sera installée dans le répertoire /usr/local/Calpont.
sudo dpkg -i calpont*release#*.deb
Le service InfiniDB Mysql utilize le port 3306, attention que si vous avez déjà une base de données utilisant le port, il faudra le modifier, pour ce faire mettez à jour le fichier /usr/local/Calpont/mysql/my.cnf
Lancement et arrêt
La commande suivante lance la base de données:
sudo /etc/init.d/infinidb start
Pour arrêter la base de données:
sudo /etc/init.d/infinidb stop
Chargement et tests
Pour les tests je recommande SQL workbench, entièrement gratuit il vous permet de lancer des commandes SQL sur n’importe quelle base de données, si celle-ci est propriétaire il suffit d’ajouter le bon jar (oracle, informix)
Le chargement des données se fait via un outil ultra rapide nommé cpimport, vous pouvez trouver un datawarehouse de test sur le site d’infobright, qui fera l’objet d’un nouvel article ^^
Voici le lien: Datawarehouse de test
Il suffit ensuite de décompresser les fichiers TXT qui contiennent les tables et de les charger une à une avec l’exécutable cpimport situé dans le répertoire /usr/local/Calpont/bin

La table de fait fact_sales est liée aux différentes dimensions (tables en dim_), la table fact_sales_wide est simplement une copie de fact_sales avec les dimensions dégénérées. Attention il faut changer le nom du moteur par INFINIDB.
Certains types ne sont pas compatibles (tinytext -> varchar ou timestamp -> date)
CREATE DATABASE carsale;
CREATE TABLE carsale.fact_sales ( vehicle_id bigint(20) DEFAULT NULL, make_id bigint(20) DEFAULT NULL, dealer_id bigint(20) DEFAULT NULL, sales_area_id bigint(20) DEFAULT NULL, msa_id bigint(20) DEFAULT NULL, trans_date date DEFAULT NULL, dlr_trans_type varchar(20), dlr_trans_amt double DEFAULT NULL, sales_person varchar(20) DEFAULT NULL, sales_commission decimal(2,1) DEFAULT NULL, sales_discount float DEFAULT NULL, record_timestamp date) ENGINE=INFINIDB DEFAULT CHARSET=ascii ;
Lancez ensuite la commande :
sudo ./cpimport -E '"' carsale fact_sales /home/js/carsales/fact_sales.txt
L’option –E identifie le caractère séparateur, attention accrochez-vous ça décoiffe ^^
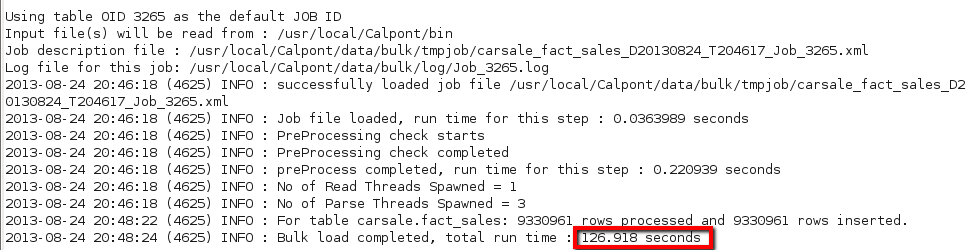
Un peu plus de deux minutes pour charger une table de 10 millions de lignes !!! pas mal du tout.
Notez au passage que le « count » ne prend que 0.76 sec
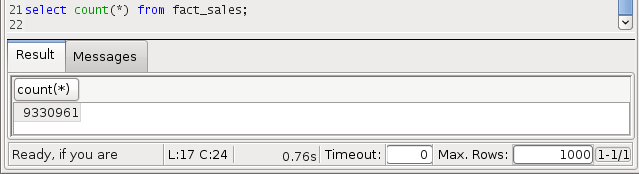
Un test d’agrégation avec la requête, il s’agit de compter toutes les ventes et achats de la table de fait:
SELECT count(*), dlr_trans_type FROM fact_sales GROUP BY dlr_trans_type;
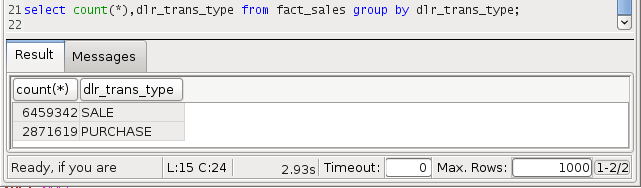
2,93 secondes pour s’exécuter, les performances sont au rendez-vous !!!
Avantages et inconvénients
Je terminerai cet article par un comparatif des « pour » et des « contre » de l’utilisation de cette base de données.
Pour
- Base de données ultra rapide permettant l’analytique sur fort volume de données.
- Evite la gestion des index
- Open source grâce à une version communautaire
- Outil de chargement de données ultra rapide également (mode bulk)
- Basé sur MySql en frontend, syntaxe identique
- Driver de connexion identique à celui d’une DB mysql classique
- Utilisation du client de requête SQL classique
Contre
- Arrêt de la version communautaire stable à 2.2.11
- Pas pour une gestion relationnel classique, des insert ou delete ne sont pas performants.
Très bon article, qui m’intéresse évidemment beaucoup. 🙂
Merci!
Avec plaisir 😉
Bonjour
En effet, InfiniDB est une base en colonne très rapide…
… quand elle ne crashe pas !
Nous venons de finaliser un benchmark complet de cette base contre une autre en colonnes beaucoup plus intéressantes, malgré quelques petits défauts (MonetDB).
Ccncernant InfiniDB, dès qu’il n’y a plus assez de mémoire sur la machine ou que le nb d’utilisateurs simultanés se connectant à la base devient trop important : ciao vos requêtes…
A éviter donc 😉
(Ou voir la version commerciale, mais autant voir plus large dans ce cas)
Bonjour,
Merci de ce retour 😉 sur ce blog je ne m’intéresse qu’aux versions gratuites, j’avoue avoir fait de rapides tests et jamais de mise en production.
J’ai réussi à connecter Saiku et à faire des tests OLAP sur du court terme avec de très bons temps de réponse.
D’ailleurs j’ai remarqué (sauf erreur de ma part) que Calpont à fait volte-face par rapport à l’open source car la version communautaire n’est plus accessible en téléchargement, faisant tomber un peu mon article dans la désuétude 🙁